Amazon SageMaker Model Monitor – Detecting Language Data Drift
Amazon SageMaker Model Monitor – Detecting Language Data Drift
It’s been a few months since we last spoke about language data and the AWS tools made to navigate NLP (Natural Language Processing) data drift. Within that time, the specialist AI/ML Solutions Architects within the Amazon SageMaker team have refined Amazon SageMaker Model Monitor to better detect and combat this drift. In this AWS insight, we look at an AWS approach to detecting data drift in text data, as well as running through some of the basic terminology.
What’s Natural Language Processing (NLP)?
NLP is a field of computer science that deals with applying linguistic and statistical algorithms to text in order to extract meaning in a way that is very similar to how the human brain understands language.
What’s data drift?
So, the short and skinny version would be, imagine looking at two versions of the same or similar datasets, both taken at different times. When you do a comparative review of each of these datasets, if the data histograms do not overlap significantly, we say that data has drifted.
So what have AWS been working on to help?
Amazon SageMaker Model Monitor is helping to continuously monitor the quality of your ML models in real time! With Model Monitor, you can configure alerts to notify and trigger actions if any drift in model performance is observed. Early and proactive detection of these deviations allows you to take corrective actions, such as collecting new ground truth training data, retraining models, auditing upstream systems, without having to manually monitor models or build additional tooling.
Model Monitor currently offers four different types of monitoring capabilities to detect and mitigate model drift in real time:
• Data quality – Helps detect change in data schemas and statistical properties of independent variables and alerts when a drift is detected.
• Model quality – For monitoring model performance characteristics such as accuracy or precision in real time – Model Monitor allows you to ingest the ground truth labels collected from your applications. Model Monitor then automatically merges the ground truth information with prediction data to compute the model performance metrics.
• Model bias – Model Monitor is integrated with Amazon SageMaker Clarify to improve visibility into potential bias. Although your initial data or model may not be biased, changes in the world may cause bias to develop over time in a model that has already been trained.
• Model explainability – Drift detection alerts you when a change occurs in the relative importance of feature attributions.
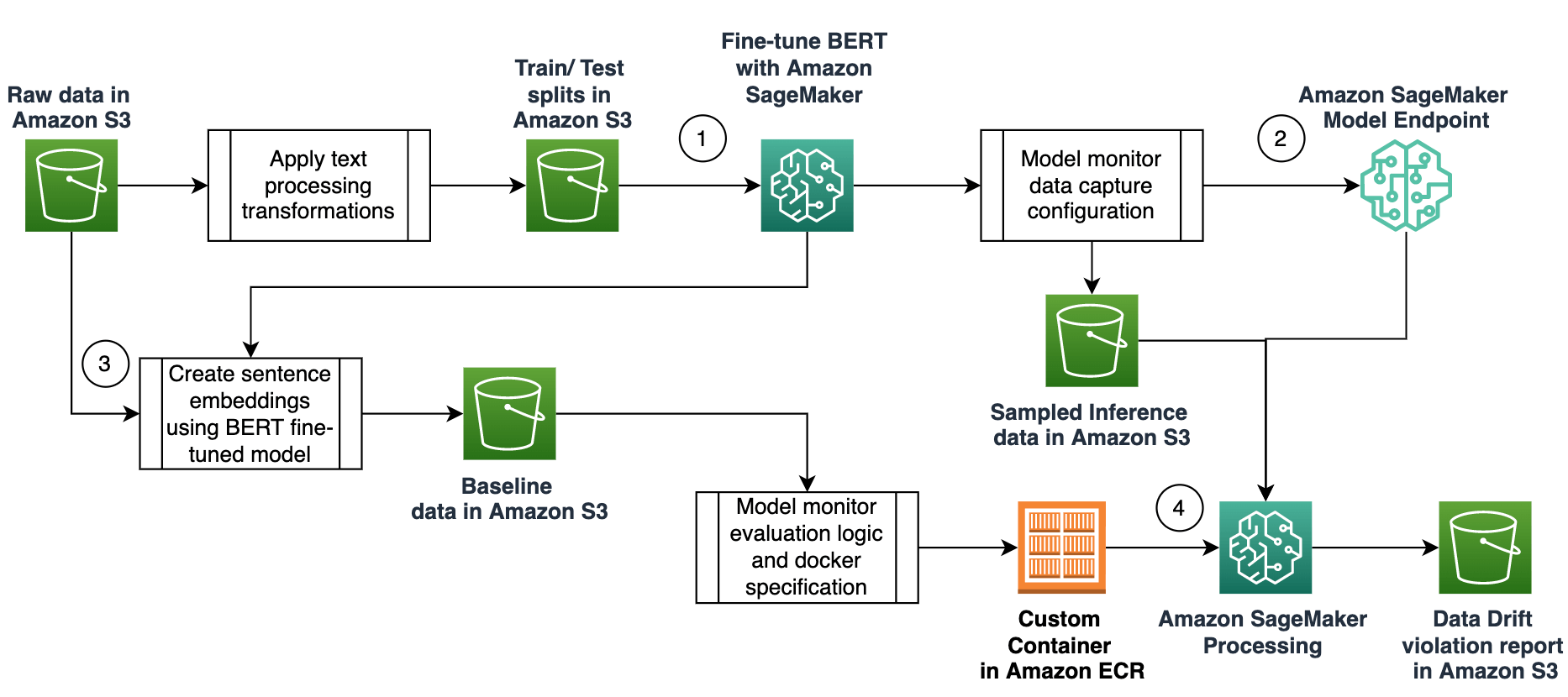
Data Drift Classifications
Data drift can be classified into three core categories, depending on whether the distribution shift is happening on the input or on the output side (or whether the relationship between the input and the output has changed).
Covariate Shift
In a covariate shift, the distribution of inputs changes over time, but the conditional distribution P(y|x) doesn’t change. This type of drift is called Covariate shift because the problem arises due to a shift in the distribution of the covariates (aka features).
Label Shift
While Covariate shift focuses on changes in the feature distribution, label shift focuses on changes in the distribution of the class variable. This type of shifting is essentially the reverse of Covariate shift. An intuitive way to think about it might be to consider an unbalanced dataset. If the spam to non-spam ratio of emails in our training set is 50%, but in reality 10% of our emails are non-spam, then the target label distribution has shifted 👍.
Concept Shift
Concept shift is different from covariate and label shift in that it’s not related to the data distribution or the class distribution, but instead relates to the relationship between the two variables. For example, email spammers often use a variety of concepts to pass the spam filter models and the concept of emails used during training may change as time goes by.
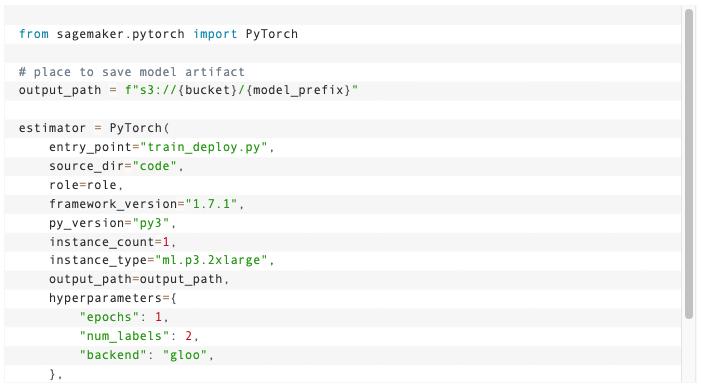
Follow the full solution and step by steps
If you’d like to see the granular steps and follow the guide through creating baselines, evaluating scripts, using Model Monitor custom containers and more, click here.
If you’re in a position where you have exemplary amounts of data and no idea how to collect, archive and retrieve (whilst minimising drift) in a secure, fast and cost efficient manner, reach out to us using the form below!
… [Trackback]
[…] Read More to that Topic: ismeandco.com/amazon-sagemaker-model-monitor-detecting-language-data-drift/ […]
… [Trackback]
[…] Read More on that Topic: ismeandco.com/amazon-sagemaker-model-monitor-detecting-language-data-drift/ […]